Most people searching for “random numbers in SQL Server” want one of two things:
- A random value they can use for test data
- Rows to come back in a random order
SQL Server gives you two common tools for this: RAND() and NEWID(). They solve different problems, and confusion usually starts when they are treated as interchangeable.
This post shows how to use both, starting with simple examples, and explains why they behave the way they do once you use them in real queries.
Generating Random Numbers with RAND()
The most common use of RAND() is generating a random number for test data.
-- Random integer between 1 and 100
SELECT CAST(RAND() * 100 + 1 AS int) AS RandomNumber;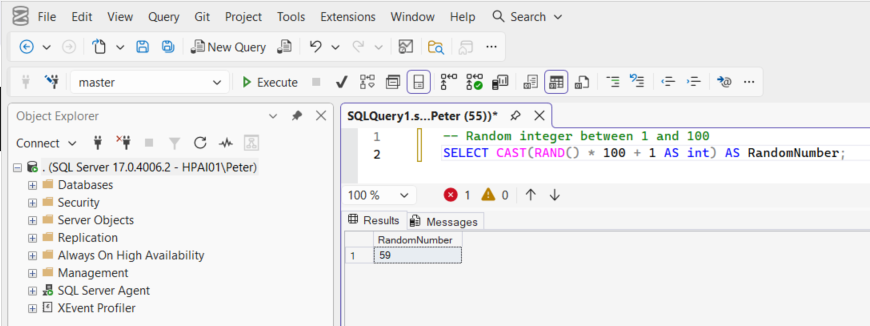
For a single value, this behaves exactly how most people expect.
You can use the same pattern to generate dates, percentages, or values in any numeric range by adjusting the multiplier. That makes RAND() useful when you want controlled randomness, especially during testing.
You can also seed it:
-- Generate a repeatable random value using a seed
SELECT CAST(RAND(42) * 100 + 1 AS int) AS SeededRandom;Seeding is useful when you want the same value every time, for example when recreating a test scenario or debugging behaviour.
Why RAND() Behaves Strangely in Queries
Things get confusing when you try to use RAND() across multiple rows.
-- RAND() is evaluated once and reused for all rows
SELECT
name,
CAST(RAND() * 100 + 1 AS int) AS RandomNumber
FROM sys.databases;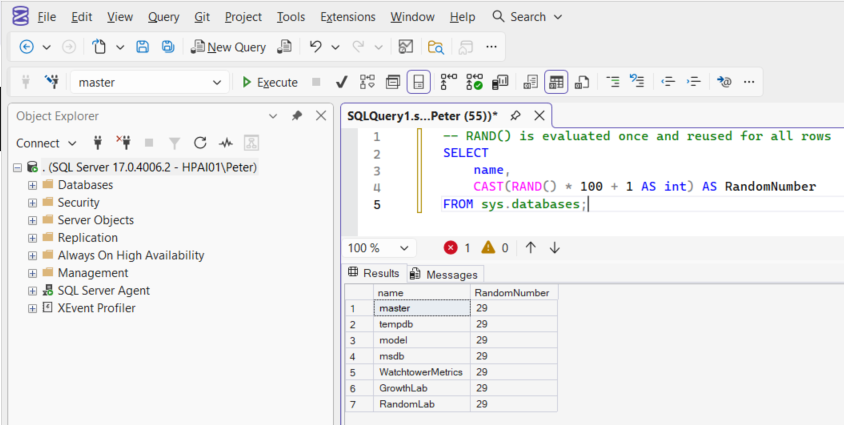
Every row returns the same number.
This is not a bug. RAND() is calculated once when the query starts, and that single value is reused for all rows in the result set.
That makes RAND() a poor fit when you want different random values per row, but it is still useful when you intentionally want one random value applied consistently.
When RAND() Makes Sense
RAND() works well when:
- You want one random value reused across a query
- You need repeatable test data
- You are generating a single value at a time
It does not work well for per-row randomness.
That’s where NEWID() comes in.
Using NEWID() to Introduce Per-Row Randomness
NEWID() generates a unique identifier every time it is called.
-- Generate a unique identifier
SELECT NEWID() AS UniqueValue;The important difference is that NEWID() is generated per row, not once per query. That makes it useful when you want variation across rows.
A common pattern is to turn it into a number:
-- Generate a different numeric value per row
SELECT
name,
ABS(CHECKSUM(NEWID())) % 100 + 1 AS RandomNumber
FROM sys.databases;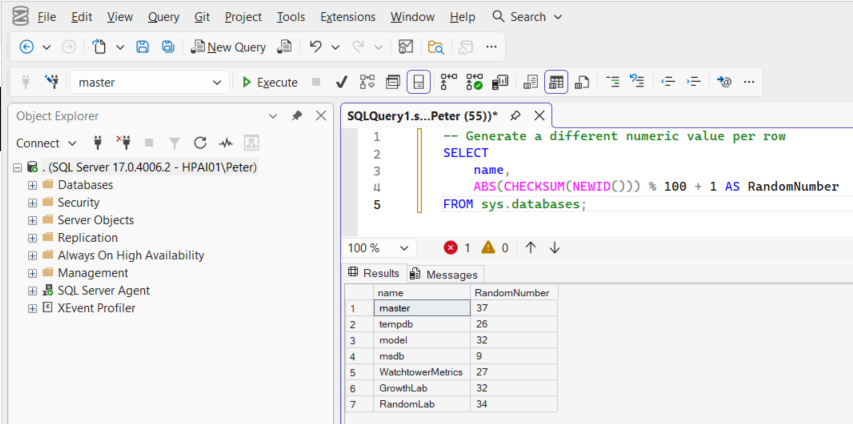
Each row now gets a different value.
This approach is widely used for test data generation, sampling, and situations where RAND() does not behave as required.
Randomising Row Order with ORDER BY NEWID()
The most common use of NEWID() is shuffling rows.
-- Return rows in a random order
SELECT *
FROM sys.objects
ORDER BY NEWID();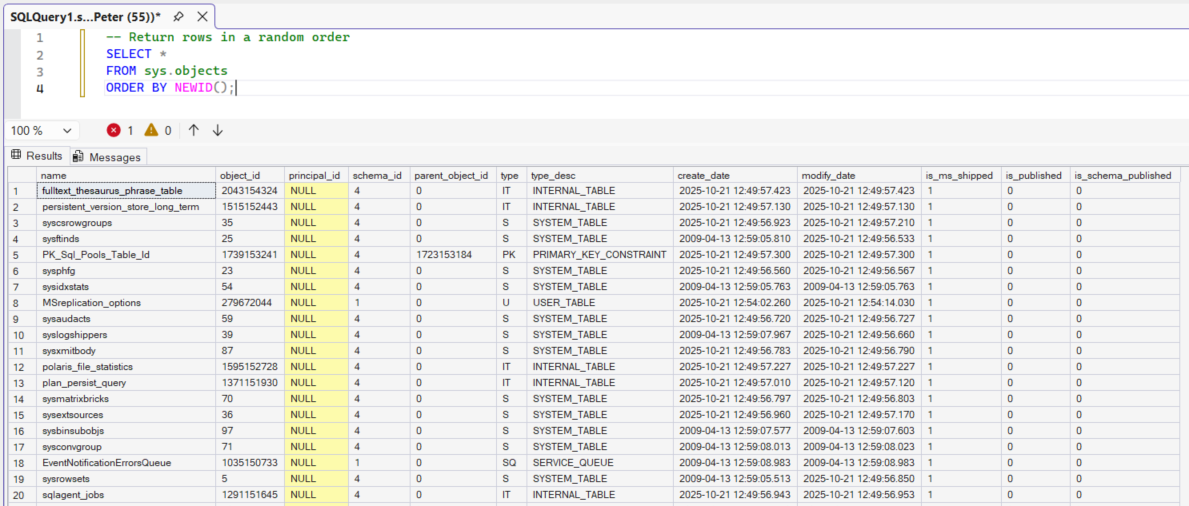
Each row is assigned a unique value and then sorted by it, resulting in a random order.
This is useful for sampling rows, testing assumptions about ordering, or one-off investigation queries.
It works well for small datasets, but it does not scale. Sorting on a generated value forces SQL Server to do extra work, which becomes expensive on large tables. If performance matters, this technique needs care.
Choosing Between RAND() and NEWID()
The choice comes down to what you need.
Use RAND() when you want:
- A simple random value
- Optional repeatability
- One value reused consistently
Use NEWID() when you want:
- Different values per row
- Randomised ordering
- Variation rather than repeatability
They are not interchangeable, and most problems come from using the right tool in the wrong place.
What this does not solve
Neither RAND() nor NEWID() is suitable for generating secrets.
RAND() is a pseudo-random number generator. Given the same conditions or seed, it produces predictable results. That is useful for testing, but it is the opposite of what you want for things like passwords or tokens.
NEWID() generates values that are unique, not secret. GUIDs are designed to avoid collisions, not to be hard to guess, and SQL Server does not treat them as cryptographically secure.
Both functions are intended for data shaping and query behaviour, not for generating passwords, access tokens, or encryption material. If unpredictability matters, secure randomness should come from the operating system or application-level cryptographic tooling, not from these functions.
They also behave very differently under load, which becomes important once you start randomising large result sets. That topic deserves its own discussion.
Leave a Reply